
صنعت هوش مصنوعی چین بهسرعت در حال رشد است و به تهدیدی جدی برای شرکتهای فناوری آمریکایی تبدیل شده است. در این مطلب، به بررسی دلایل این پیشرفت میپردازیم.
در ماه سپتامبر، OpenAI اولین مدل استدلالی جهان را که نوعی پیشرفته از هوش مصنوعی محسوب میشود، معرفی کرد. این مدل که با نام o1 شناخته میشود، از روش «زنجیره تفکر» برای حل مسائل پیچیده در حوزههای علوم و ریاضیات بهره میبرد. عملکرد این مدل بهگونهای است که قبل از ارائه پاسخ نهایی، دادهها را تحلیل کرده و راهکارهای مختلف را در پسزمینه بررسی میکند. این نوآوری باعث شد رقبا برای ارائه مدلهای مشابه وسوسه شوند. در واکنش به این فناوری، گوگل در ماه دسامبر مدل استدلالی خود را با نام Gemini Flash Thinking عرضه کرد. مدت کوتاهی پس از آن، OpenAI نیز نسخه جدیدی از مدل خود، o3، را معرفی کرد.
بااینحال، گوگل تنها شرکتی نبود که از OpenAI الهام گرفت. تنها سه ماه پس از رونمایی از o1، غول تجارت الکترونیک چین، علیبابا، نسخه جدید چتبات خود به نام کوئن (Qwen) را ارائه کرد که قابلیتهای استدلالی مشابهی داشت. این شرکت در یک پست وبلاگی پرزرقوبرق، همراه با لینکی به نسخه رایگان مدل، این پرسش را مطرح کرد. »تفکر، پرسش و درک چه مفهومی دارد؟ «علاوه بر علیبابا، شرکت چینی دیگری به نام دیپ سیک (DeepSeek) نیز یک هفته پیش از آن، مدل استدلالی R1 را منتشر کرده بود.
این پیشرفتها در حالی رخ میدهند که دولت آمریکا تلاش کرده با اعمال محدودیتها، صنعت هوش مصنوعی چین را عقب نگه دارد. اما با وجود این موانع، شرکتهای چینی موفق شدهاند فاصله خود را با رقبای آمریکاییشان کاهش دهند و تنها چند هفته پس از انتشار فناوریهای جدید از سوی شرکتهای آمریکایی، مدلهای مشابهی را به بازار عرضه کنند.
البته این شرکتها فقط در توسعه مدلهای استدلالی فعال نیستند. در ماه دسامبر، دیپ سیک مدل زبانی بزرگ جدیدی به نام v3 را منتشر کرد که دارای ۶۸۵ میلیارد پارامتر و حجمی در حدود ۷۰۰ گیگابایت است. به دلیل حجم بالای این مدل، اجرای آن تنها بر روی سختافزارهای تخصصی امکانپذیر است. در مقایسه، مدل Llama 3.1 که پرچمدار متا محسوب میشود و در ماه ژوئیه معرفی شد، تنها ۴۰۵ میلیارد پارامتر دارد.(نمودار زیر را ببینید.)
همه این پیشرفتها نشان میدهند که صنعت هوش مصنوعی چین با سرعتی چشمگیر در حال حرکت است و به رقیبی جدی برای شرکتهای آمریکایی تبدیل شده است.
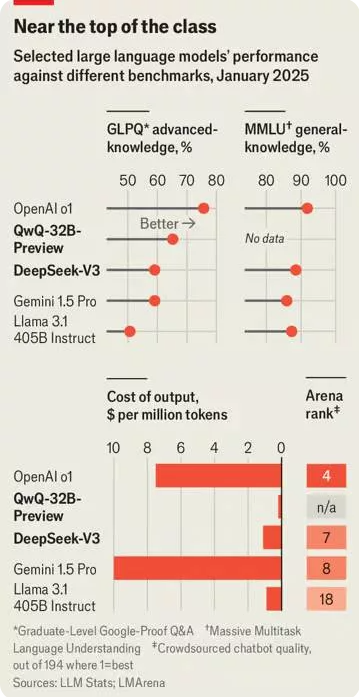
مدل زبانی بزرگی که دیپ سیک توسعه داده، نهتنها از بسیاری از همتایان غربی خود حجیمتر است، بلکه از جنبههایی نسبت به آنها برتری دارد و میتواند با مدلهای اختصاصی گوگل و OpenAI رقابت کند. پل گوتیه (Paul Gauthier)، بنیانگذار Aider، پلتفرم کدنویسی مبتنی بر هوش مصنوعی، مدل v3 را روی بنچمارک اختصاصی کدنویسی خود آزمایش کرد و دریافت که این مدل، بهجز o1، از تمامی رقبا عملکرد بهتری دارد. در رتبهبندی Lmsys که به ارزیابی چتباتها میپردازد، v3 در جایگاه هفتم قرار گرفته است. این موقعیت نشان میدهد که مدل دیپ سیک، نسبت به تمام مدلهای متنباز موجود، برتری دارد و بهترین مدلی محسوب میشود که توسط شرکتی غیر از گوگل یا OpenAI ساخته شده است.
در حال حاضر، پیشرفتهای صنعت هوش مصنوعی چین به حدی رسیده که فاصله آن با رقبای آمریکایی بهشدت کاهش یافته است. این موضوع باعث شده سم آلتمن، مدیرعامل OpenAI، دراینباره واکنش نشان دهد. او مدت کوتاهی پس از انتشار مدل v3 از سوی دیپ سیک، در توییتی با لحنی ناخوشایند نوشت: «کپیکردن چیزی که میدانید جواب میدهد (نسبتاً) آسان است، اما انجام کاری نوآورانه، پرخطر و نامطمئن، بهمراتب دشوارتر است».
دلایل پیشرفت صنعت هوش مصنوعی در چین

در ابتدا، صنعت هوش مصنوعی چین در مقایسه با رقبای غربی، بهویژه آمریکا، عقبتر به نظر میرسید. یکی از دلایل این موضوع، تحریمهای ایالات متحده علیه چین بود. در سال ۲۰۲۲، آمریکا صادرات تراشههای پیشرفته به چین را ممنوع کرد و شرکت انویدیا، یکی از برترین تولیدکنندگان پردازندههای گرافیکی، مجبور شد نسخههایی با کارایی محدودتر برای بازار چین طراحی کند. علاوه بر این، واشنگتن با محدودیتهای مختلف، از جمله جلوگیری از فروش تجهیزات ضروری برای ساخت تراشههای پیشرفته، تلاش کرد مانع پیشرفت چین در این حوزه شود. حتی شرکتهای غیرآمریکایی که احتمال همکاری با چین را داشتند، با تهدید تحریم مواجه شدند.
علاوه بر این محدودیتهای خارجی، چالشهای داخلی نیز بر روند توسعه هوش مصنوعی در چین تأثیر گذاشتند. شرکتهای فناوری این کشور نسبتاً دیرتر به سمت مدلهای زبانی بزرگ روی آوردند که یکی از دلایل آن، دغدغههای نظارتی بود. مسئولان چینی نگران بودند که این مدلها دچار خطاهای محتوایی شوند، اطلاعات نادرست تولید کنند یا حتی جملاتی با بار سیاسی حساس ارائه دهند. برای مثال، شرکت بایدو که موتور جستجوی اصلی چین را در اختیار دارد، مدتها مشغول آزمایش مدل زبانی ERNIE بود اما برای انتشار عمومی آن تردید داشت. حتی پس از موفقیت ChatGPT، این شرکت رویکردی محتاطانه در پیش گرفت و دسترسی به چتبات ERNIEbot را تنها از طریق دعوتنامه ممکن ساخت.
در نهایت، دولت چین با وضع مقررات جدید، مسیر توسعه هوش مصنوعی را هموارتر کرد. در حالی که از توسعهدهندگان خواسته شد محتوای تولیدشده توسط مدلهایشان با ارزشهای سوسیالیستی سازگار باشد، از نوآوری در این حوزه نیز حمایت شد.
یکی از نمونههای تحول در هوش مصنوعی چین، مدل Qwen از شرکت علیبابا است. در ابتدا، این مدل تفاوت چندانی با نسخههای متنباز موجود مانند Llama شرکت متا نداشت. اما از سال ۲۰۲۴، علیبابا با عرضه نسخههای بهروزرسانیشده، بهبود چشمگیری در کیفیت آن ایجاد کرد.
جک کلارک (Jack Clark)، پژوهشگر فعال در آزمایشگاه هوش مصنوعی غربی Anthropic، یک سال پیش، زمانی که Qwen برای اولینبار عرضه شد و تنها از پردازش متن و تصویر پشتیبانی میکرد، درباره مدلهای زبانی چین اظهار داشت: «این مدلها بهنظر میرسد توانایی رقابت با پیشرفتهترین مدلهایی را دارند که در آزمایشگاههای برتر غرب توسعه یافتهاند.»
شرکتهای بزرگ فناوری چین، از جمله هواوی و تنسنت، در حال توسعه مدلهای هوش مصنوعی خود هستند، اما داستان دیپ سیک متفاوت است. این شرکت حتی زمانی که علیبابا اولین مدل کوئن خود را معرفی کرد، وجود نداشت. دیپ سیک بهعنوان زیرمجموعهای از فلایر (High-Flyer) شناخته میشود. فلایر یک صندوق سرمایهگذاری مشترک است که در سال ۲۰۱۵ بهمنظور بهرهبرداری از هوش مصنوعی برای کسب مزیت در بازار سهام تأسیس شد.
با این حال، انگیزههای شرکتهای چینی در حوزه هوش مصنوعی تنها به جنبههای تجاری محدود نمیشود. «لیانگ ونفنگ»، بنیانگذار فلایر، اشاره کرده است که نخستین حامیان OpenAI بهدنبال سودآوری نبودند و انگیزههای اصلی آنها «دنبال کردن مأموریت» بوده است. در سال ۲۰۲۳، هنگامی که کوئن راهاندازی شد، فلایر اعلام کرد که قصد دارد وارد رقابت برای ایجاد هوش مصنوعی سطح انسان شود و در این راستا واحد تحقیقاتی هوش مصنوعی خود را با نام دیپ سیک راهاندازی کرد.
دیپ سیک، مشابه OpenAI، متعهد به توسعه هوش مصنوعی برای منافع عمومی شده است. لیانگ نیز تأکید کرده که این شرکت نتایج آموزشهای خود را بهصورت عمومی منتشر خواهد کرد تا از «انحصاری شدن» این فناوری در دست عدهای خاص جلوگیری کند. برخلاف OpenAI که برای تأمین هزینههای آموزش خود مجبور به جلب سرمایه خصوصی شد، دیپ سیک همواره به منابع محاسباتی عظیم فلایر دسترسی داشته است.ویژگی برجسته مدل زبان دیپ سیک تنها به مقیاس آن محدود نمیشود، بلکه مصرف کم انرژی در فرایند آموزش نیز توجهها را جلب کرده است. در این فرایند، مدل با استفاده از دادهها، پارامترهای خود را استنتاج میکند. به گفته نیک لین از دانشگاه کمبریج، این موفقیت بهدلیل نوآوری بزرگ نبوده بلکه حاصل بهبودهای تدریجی در فرآیندهای مختلف است. به عنوان مثال، معمولاً در فرایند آموزش برای سادهسازی محاسبات از گردکردن استفاده میشود، اما در صورت لزوم، اعداد با دقت حفظ میشوند. علاوه بر این، مزرعه سرور بهگونهای بازپیکربندی شده که تراشهها بهطور کارآمدتری با یکدیگر ارتباط برقرار کنند. در نهایت، مدل پس از آموزش، با استفاده از خروجی سیستم استدلال DeepSeek R1، بهطور دقیق تنظیم شد تا بتواند کیفیت سیستم را با هزینه کمتری تقلید کند
به لطف این نوآوریها و دیگر دستاوردها، ساخت مدل v3 با میلیاردها پارامتر کمتر از ۳ میلیون ساعت محاسباتی نیاز داشت و هزینه آن بهطور تقریبی کمتر از ۶ میلیون دلار بود. قدرت محاسباتی و هزینهای که برای ساخت v3 صرف شد، فقط یکدهم قدرت محاسباتی و هزینهای است که برای ساخت Llama 3.1 نیاز بود. برای آموزش v3 تنها از ۲۰۰۰ تراشه استفاده شد، در حالی که برای آموزش Llama 3.1 از ۱۶۰۰۰ تراشه استفاده گردید. نکته قابل توجه این است که به دلیل تحریمهای ایالات متحده، تراشههای استفادهشده در v3 حتی از قدرتمندترین تراشهها هم نبودند. به نظر میرسد شرکتهای غربی در استفاده از تراشهها بسیار آزادانه عمل میکنند؛ برای مثال، متا قصد دارد یک مزرعه سرور با ۳۵۰ هزار تراشه بسازد.
v3 نه تنها با هزینه کمتری نسبت به سایر مدلها آموزش داده شده، بلکه اجرای آن نیز هزینه کمتری دارد. دیپ سیک وظایف را بهطور کارآمدتری بین تراشهها تقسیم میکند و قبل از پایان مرحله قبلی، مرحله بعدی را آغاز میکند. این امر به آنها این امکان را میدهد که از ظرفیت تمام تراشهها بهطور کامل استفاده کرده و کمترین فشار کاری را داشته باشند. دیپ سیک قصد دارد در آیندهای نزدیک به دیگر شرکتها اجازه دهد تا خدماتی بر پایه توانمندیهای v3 ارائه کنند. اگر چنین خدماتی فراهم شود، هزینه استفاده از این مدل کمتر از یکدهم هزینه استفاده از مدل زبانی بزرگ آنتروپیک خواهد بود. سیمون ویلیسون، کارشناس هوش مصنوعی، درباره این موضوع گفته است: «اگر عملکرد مدلهای زبانی بزرگ چینی با مدلهای مشابه غربی رقابت کند، شاهد یک رقابت جدی در زمینه هزینه استفاده از این مدلها خواهیم بود.»
تلاشهای دیپ سیک برای افزایش کارایی تنها به اینجا ختم نمیشود؛ این شرکت علاوهبر انتشار نسخه کامل مدل R1، مجموعهای از نسخههای کوچکتر، ارزانتر و سریعتر «پالایششده» آن را نیز منتشر کرده که تقریباً به اندازه مدل اصلی قدرتمند هستند. این اقدام دیپ سیک مشابه بهروزرسانیهای مدلهای مشابه علیبابا و متا است و بار دیگر نشان میدهد که این شرکت میتواند با بزرگترین نامهای تجاری رقابت کند.
علیبابا و دیپ سیک در زمینهای دیگر نیز با آزمایشگاههای پیشرفته غربی رقابت میکنند؛ این دو شرکت برخلاف OpenAI و گوگل، مانند متا سیستمهای خود را با مجوز منبعباز در دسترس قرار میدهند. اگر بخواهید هوش مصنوعی کوئن را دانلود کنید و پلتفرم برنامهنویسی خود را بر اساس آن بسازید، میتوانید این کار را به راحتی انجام دهید و نیازی به مجوز خاصی نخواهید داشت. این آزادی عمل موجب شفافیت فوقالعادهای میشود؛ هر دو شرکت پس از انتشار مدلهای جدید، مقالاتی منتشر میکنند که جزئیات زیادی درباره تکنیکهای بهکاررفته برای بهبود عملکرد آنها ارائه میدهند.
دلایل رقابتپذیری مدلهای هوش مصنوعی چینی با نمونههای مشابه آمریکایی

زمانی که علیبابا مدل QwQ را با نام کامل «Questions with Qwen» منتشر کرد، این شرکت به اولین شرکت جهانی تبدیل شد که چنین مدلی را با مجوز باز عرضه میکند. علیبابا به کاربران این امکان را میدهد که فایل کامل ۲۰ گیگابایتی مدل را دانلود کرده و آن را روی سیستم خود اجرا کنند یا حتی بتوانند آن را تفکیک کرده و نحوه عملکردش را بررسی کنند. این رویکرد بهطور قابلتوجهی با رویکرد OpenAI که کارکردهای داخلی مدل o1 خود را پنهان میکند، متفاوت است.
هر دو مدل بهطور کلی از «محاسبات در زمان آزمون» استفاده میکنند. در این روش، برخلاف تمرکز بر قدرت محاسباتی در زمان آموزش، هنگام پاسخ به سؤالات، مدل بیشتر از نسلهای قبلی مدلهای زبانی بزرگ منابع محاسباتی مصرف میکند. این روش بهویژه در زمینههایی مانند ریاضیات و برنامهنویسی نتایج امیدوارکنندهای به همراه داشته است.
برای مثال، اگر از شما سؤال سادهای مثل «نام پایتخت فرانسه چیست؟» پرسیده شود، شما احتمالاً بهطور فوری پاسخ خواهید داد و احتمالاً جواب درست خواهد بود. چتباتهای معمولی نیز به همین روش عمل میکنند. اما اگر سؤالی پیچیدهتر مانند «پنجمین شهر پرجمعیت فرانسه کدام است؟» مطرح شود، شما احتمالاً ابتدا فهرستی از شهرهای بزرگ فرانسه تهیه کرده و سپس آنها را بر اساس جمعیت مرتب خواهید کرد و سپس به جواب خواهید رسید.
مدلهای مانند o1 سعی دارند مدلهای زبان بزرگ را بهسمت این نوع تفکر ساختاری هدایت کنند. این سیستمها به جای اینکه سریعاً بهدنبال پاسخهای قابلقبول بروند، ابتدا مسئله را تجزیه کرده و مرحله به مرحله به پاسخ میرسند. OpenAI معمولاً افکار خود را نگه میدارد و تنها خلاصهای از فرآیند و نتیجه نهایی را به کاربر نشان میدهد. این تصمیمات بهویژه زمانی مهم هستند که مدل ممکن است درباره استفاده از کلمات حساس یا افشای اطلاعات خطرناک فکر کند و سپس تصمیم بگیرد که آنها را فاش نکند.
در مقابل، علیبابا هیچگونه نگرانیای در این زمینه ندارد. اگر از مدل QwQ خواسته شود تا یک مسئله ریاضی پیچیده را حل کند، این مدل بدون هیچگونه توقفی، هر مرحله از حل مسئله را با جزئیات شرح میدهد و حتی ممکن است هزاران کلمه را برای امتحان روشهای مختلف بهکار برده و به تفصیل توضیح دهد.
ایسو کانت، همبنیانگذار شرکت پول ساید (Poolside) که ابزارهای هوش مصنوعی برای برنامهنویسان تولید میکند، معتقد است که مدل متنباز علیبابا تصادفی نیست. آزمایشگاههای چینی در حوزه هوش مصنوعی مانند سایر صنایع، در تلاش هستند تا استعدادهای زیادی جذب کنند.
البته مدلهای چینی مشکلاتی هم دارند؛ بهعنوان مثال، اگر از مدل DeepSeek v3 درباره تایوان سؤال کنید، مدل پاسخ میدهد که تایوان جزیرهای در شرق آسیاست و بخشی از جمهوری چین محسوب میشود. اما پس از چند جمله توضیح در این زمینه، پاسخ خود را متوقف کرده و تنها میگوید: «بیایید درباره چیز دیگری صحبت کنیم!»
آزمایشگاههای هوش مصنوعی چینی برخلاف دولت چین، رویکرد شفافتری دارند؛ چرا که هدفشان ساخت یک اکوسیستم تجاری حول فناوری هوش مصنوعی است. چنین رویکردی مزیت تجاری دارد زیرا شرکتهایی که بر پایه مدلهای متنباز ساخته میشوند، ممکن است در نهایت تمایل پیدا کنند محصولات یا خدماتی از تولیدکنندگان این مدلها خریداری کنند. همچنین، این رویکرد میتواند در رقابتهای چین و آمریکا در زمینه هوش مصنوعی، مزیت استراتژیک بهدست آورد.
بهطور کلی، شرکتهای چینی ترجیح میدهند از مدلهای هوش مصنوعی ساخت چین استفاده کنند زیرا دیگر نیازی نیست نگران محدودیتها، ممنوعیتها و تحریمهایی باشند که شرکتهای غربی بهطور مداوم اعمال میکنند. علاوه بر این، آنها دیگر نیازی به نگرانی در مورد سانسورهایی که در داخل چین باید انجام شوند، نخواهند داشت، مسائلی که مدلهای غربی به آن توجه نمیکنند.
فرانسیس یانگ، سرمایهگذار حوزه فناوری مستقر در شانگهای، اشاره کرده که همکاری شرکای محلی با شرکتهایی نظیر اپل و سامسونگ که به دنبال استفاده از هوش مصنوعی در دستگاههای خود برای فروش در چین هستند، ضروری است. حتی برخی از شرکتهای خارجی دلایل خاص خود را برای استفاده از مدلهای چینی دارند. بهعنوان مثال، کوئن عمداً روی زبانهایی مثل اردو و بنگالی که منابع داده کمتری در دسترس دارند، تمرکز کرده و به همین دلیل، میتوان گفت که این مدل با منابع بیشتری آموزش داده شده است. در مقابل، مدلهای آمریکایی بیشتر با دادههای انگلیسی آموزش میبینند. همچنین، همانطور که گفته شد، هزینه پایین اجرای مدلهای چینی موجب جذابیت بیشتر آنها میشود.
آیا صنعت هوش مصنوعی چین تهدیدی جدی برای آمریکا است؟
در پایان باید اشاره کنیم که حمایت از مدلهای هوش مصنوعی و چتباتهای چینی به معنای تضمین پیشرفت آنها در آینده نیست. پلتفرمهای هوش مصنوعی آمریکایی هنوز قابلیتهایی دارند که در رقبای چینی مشاهده نمیشود. برای مثال، چتباتهای کلاد و OpenAI نهتنها در نوشتن کدها کمک میکنند بلکه در اجرای آنها نیز نقش دارند. کلاد توانایی ایجاد و میزبانی تمام اپلیکیشنها را دارد. همچنین، استدلال گامبهگام تنها روش حل مسائل پیچیده نیست؛ شما میتوانید همان سؤال ریاضی را از نسخه معمولی ChatGPT بپرسید و این چتبات با نوشتن یک برنامه ساده برای حل آن به شما کمک میکند.
گفته میشود که OpenAI بهزودی از راهاندازی «ابرعامل در سطح دکترا» خبر خواهد داد. این ابرعامل قادر به انجام وظایف علمی با تواناییهایی مشابه انسان است و انتظار میرود نوآوریهای جدیدی به دنبال داشته باشد. آقای آلتمن معتقد است که رقابت فعلی با صنعت هوش مصنوعی چین ممکن است به تحقق اهداف بزرگتر این صنعت منجر شود.